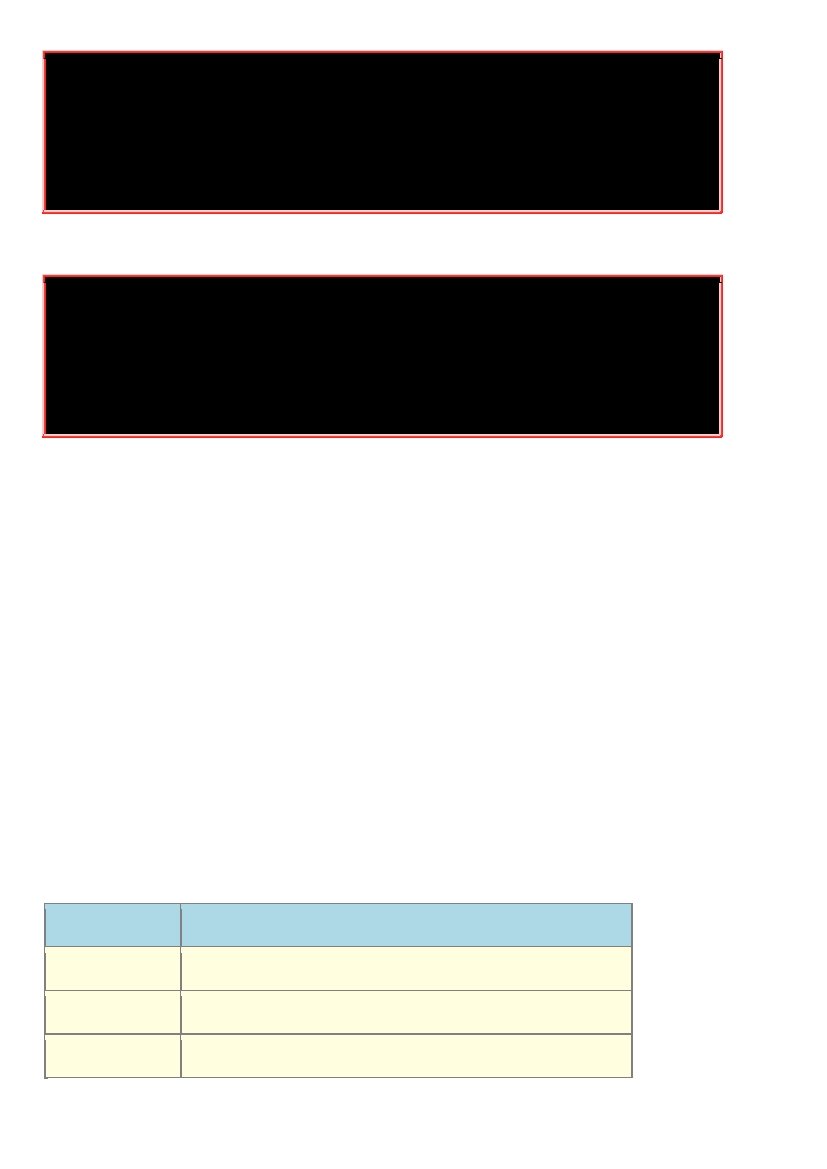
[dmtsai@study ~]$
last
-
n 5
<==
½
取出前五行
dmtsai pts/0 192.168.1.100 Tue Jul 14 17:32 still logged in
dmtsai pts/0 192.168.1.100 Thu Jul 9 23:36
-
02:58 (03:22)
dmtsai pts/0 192.168.1.100 Thu Jul 9 17:23
-
23:36 (06:12)
dmtsai pts/0 192.168.1.100 Thu Jul 9 08:02
-
08:17 (00:14)
dmtsai tty1 Fri May 29 11:55
-
12:11 (00:15)
若我想要取出账号与登入者的
IP
,且账号与
IP
之间以
[tab]
隔开,则会变成这样:
[dmtsai@study ~]$
last
-
n 5 | awk '{print $1 "
\
t" $3}'
dmtsai 192.168.1.100
dmtsai 192.168.1.100
dmtsai 192.168.1.100
dmtsai 192.168.1.100
dmtsai Fri
上表是
awk
最常使用的动作!透过
print
的功能½字段数据列出来!字段的分隔则以空格键或
[tab]
按键来隔开。
因为不论哪一行我都要处理,因此,就不需要有
"
条件类型
"
的限制!我所想要的是
第一栏以及第三栏,
但是,第五行的内容怪怪的~这是因为数据格式的问题啊!所以啰~使用
awk
的时候,请先确认一下你的数据当中,如果是连续性的数据,请不要有空格或
[tab]
在内,否则,就
会像这个例子这样,会发生误判喔!
另外,由上面这个例子你也会知道,在
awk
的括号内,
每一行的每个字段都是有变量名称的,那就
是
$1, $2...
等变量名称
。以上面的例子来说,
dmtsai
是
$1
,因为他是第一栏嘛!至于
192.168.1.100
是第三栏,
所以他就是
$3
啦!后面以此类推~呵呵!还有个变数喔!那就是
$0
,
$0
代表『一整
列资料』的意思~
以上面的例子来说,第一行的
$0
代表的就是『
dmtsai ....
』那一行啊!
由此可知,
刚刚上面五行当中,整个
awk
的处理流程是:
1.
读入第一行,并½第一行的资料填入
$0, $1, $2....
等变数当中;
2.
依据
"
条件类型
"
的限制,判断是否需要½行后面的
"
动作
"
;
3.
做完所有的动作与条件类型;
4.
若还有后续的『行』的数据,则重复上面
1~3
的步骤,直到所有的数据都读完为止。
经过这样的步骤,你会晓得,
awk
是『
以行为一次处理的单位
』,
而『
以字段为最小的处理单位
』。
好了,那么
awk
怎么知道我到底这个数据有几行?有几栏呢?这就需要
awk
的内½变量的帮忙
啦~
变量名称
代表意义
NF
每一行
($0)
拥有的字段总数
NR
目前
awk
所处理的是『第几行』数据
FS
目前的分隔字符,默认是空格键