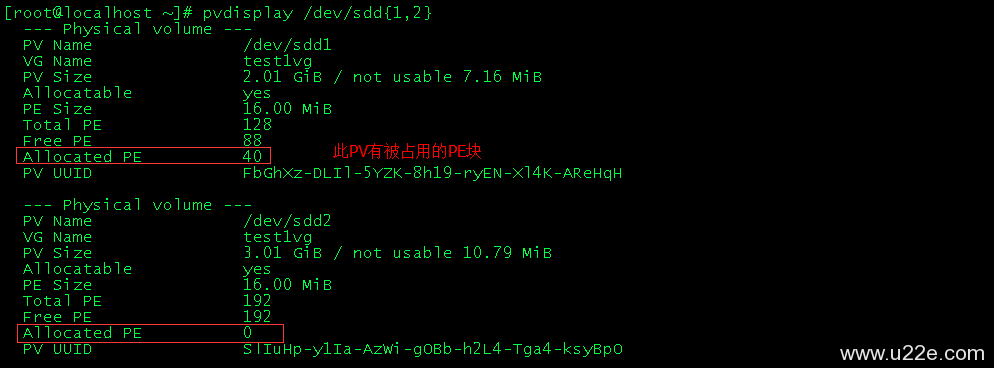
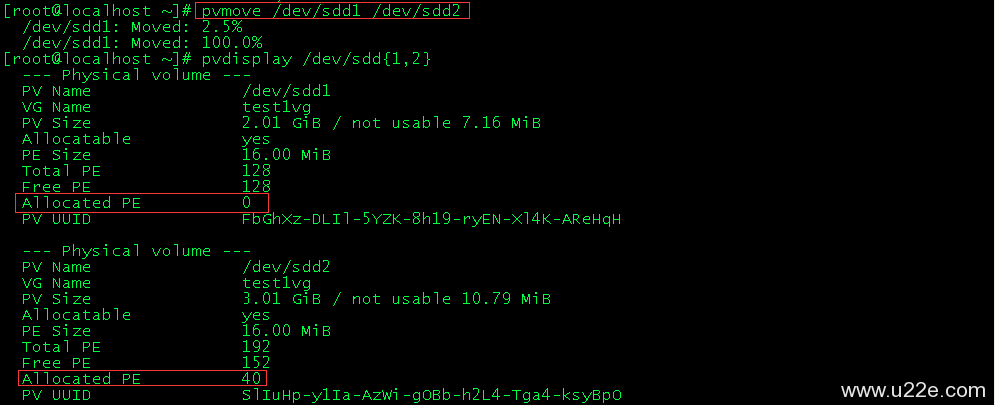
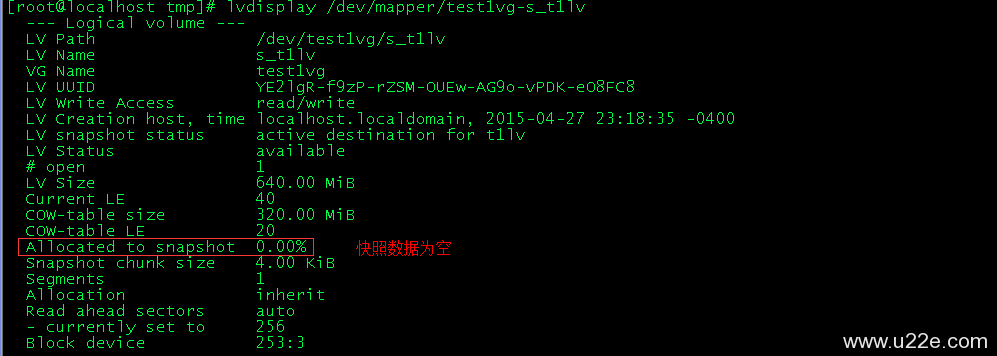
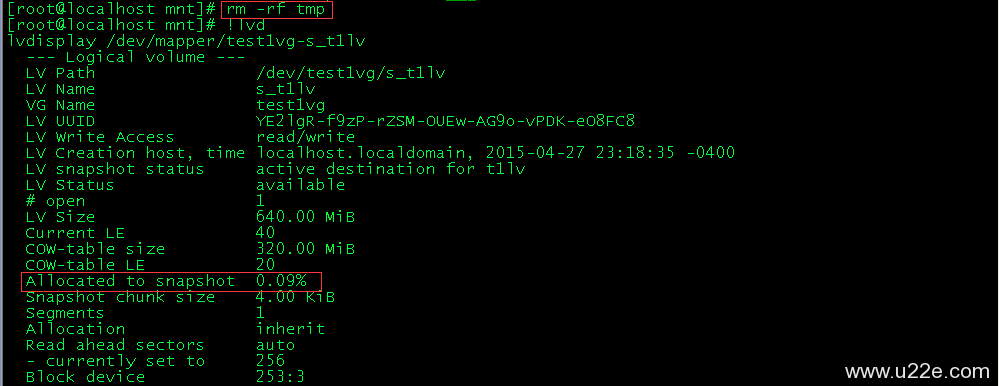
1、请描述网桥、集线器、二层交换机、三层交换机、路由器的功能、使用场景与区别。
网桥(birdge):工作于OSI模型中的数据链路层,是连接两个局域网的一种存储/转发设备,能将一个大的LAN分割为多个网段,或将两个以上的LAN互联为一个逻辑LAN,使LAN上的所有用户都可访问服务器,可以分割冲突域。
集线器(Hub):工作于OSI模型中的物理层,可以对接收到的信号进行再生和放大,并将其以广播形式发送到所有端口,可以扩大网络的传输距离,不能分割冲突域。
二层交换机(Layer 2 switches):工作于OSI模型中的数据链路层,识别数据包中的MAC地址信息,根据MAC地址进行转发,并将这些MAC地址与对应的端口记录在自己内部的一个地址表中。
三层交换机(Layer 3 switches):拥有部分路由器功能的交换机,可以加快大型局域网内部的数据交换,所具有的路由功能也是为这目的服务的,能够做到一次路由,多次转发。
路由器(Router):工作于OSI模型的网络层,连接因特网中各局域网、广域网的设备,它会根据信道的情况自动选择和设定路由,以最佳路径,按前后顺序发送信号。
2 、IP地址的分类有哪些?子网掩码的表示形式及其作用
IP地址分类:
公网地址:公网地址是由Inter NIC(Internet Network Information Center因特网信息中心)负责。这些IP地址分配给注册并向Inter NIC提出申请的组织机构。通过它直接访问因特网。
私有地址:私有地址(Private address)属于非注册地址,预留给组织或个人使用不能直接在网上直接进行访问的地址,私有地址一共分为A、B、C、D、E五类。
A类地址最大网络数为126(2^7-2),ip地址范围是0.0.0.0-127.255.255.255,最大主机数为16777214,地址范围是 10.0.0.0-10.255.255.255
B类地址最大网络数为16384(2^14),ip地址范围是128.0.0.0-191.255.255.255,最大主机数为16777214,地址范围是 10.0.0.0-10.255.255.255
C类地址最大网络数为2097152(2^21),ip地址范围是192.0.0.0-223.255.255.255,最大主机数为254,地址范围是 192.168.0.0-192.168.255.255
D类地址是组播地址,多播地址的最高位必须是“1110”,范围从224.0.0.0到239.255.255.255
E类地址是特殊的预留地址,地址范围是240.0.0.1到255.255.255.254。
子网掩码: 将某个IP地址划分成网络地址和主机地址两部分,其必须与ip地址组合使用,不能单独使用。
3、计算机网络的分成模型有哪些(OSI模型和TCP/IP模型),每一层的功能及涉及到的物理设备有哪些。

4、如何将Linux主机接入到TCP/IP网络,请描述详细的步骤。(手动指定的方式)
tui界面配置
centos6以下可以使用命令setup命令进入tui界面进行配置,centos7可使用命令nmtui命令进入界面进行配置
命令行界面
1、命令ip、ifconfig(注命令修改即时生效重启后消失)
ip addr add 172.23.200.1/24 dev eth0
ifconfig 172.23.200.1 netmask 255.255.255.0 eth0
2、修改配置文件(/etc/sysconfig/netwrok-scripts/ifcfg-eth0)修改后不能直接生效需要重启该网卡
[root@localhost ~]# vim /etc/sysconfig/network-scripts/ifcfg-eth0
BOOTPROTO=static
IPADDR=192.168.241.10
NETMASK=255.255.255.0
DEVICE=eth0
ONBOOT=yes
[root@localhost ~]# ifdown eth0 && ifup eht0
5、为Linux主机配置网络信息的方式有哪些,请描述各个过程。
1、在系统安装过程中配置的网络信息
2、使用tui界面进行网卡配置(centos5,6使用setup,centos7使用nmtui)
3、直接编辑网卡配置文件
4、使用命令ifconfig、ip进行网络信息配置
5、在拥有dhcp服务的网络中使用命令dhclient命令进行地址动态分配
6、写一个脚本,使用ping命令探测172.16.250.1-172.16.250.254之间的所有主机的在线状态;
在线的主机使用绿色显示;
不在线的主使用红色显示;
#!/bin/bash
#
#
#
PING() {
if ping -w2 $1 &>/dev/null ;then
echo -e "\033[32m $1 is up \033[0m"
else
echo -e "\033[31m $1 is down \033[0m"
fi
}
for i in `seq 1 254`;do
PING 172.16.250.$i
done
7、详细描述每个网络接口的配置文件中各个参数的含义和其所对应的值;
ifcfg-IFACE配置文件参数:
DEVICE:此配置文件对应的设备的名称;
ONBOOT:在系统引导过程中,是否激活此接口;
UUID:此设备的惟一标识;
IPV6INIT:是否初始化IPv6;
BOOTPROTO:激活此接口时使用什么协议来配置接口属性,常用的有dhcp、bootp、static、none;
TYPE:接口类型,常见的有Ethernet, Bridge;
DNS1:第一DNS服务器指向;
DNS2:备用DNS服务器指向;
DOMAIN:DNS搜索域;
IPADDR: IP地址;
NETMASK:子网掩码;CentOS 7支持使用PREFIX以长度方式指明子网掩码;
GATEWAY:默认网关;
USERCTL:是否允许普通用户控制此设备;
PEERDNS:如果BOOTPROTO的值为“dhcp”,是否允许dhcp server分配的dns服务器指向覆盖本地手动指定的DNS服务器指向;默认为允许;
HWADDR:设备的MAC地址;
NM_CONTROLLED:是否使用NetworkManager服务来控制接口;
8、如何给网络接口配置多个地址,有哪些方式?
1、使用命令ficonfig、ip 命令添加,添加的地址当前有效重启后消失。
ifconfig eth0:0 172.23.200.1 netmask 255.255.255.0
ip addr add 172.23.200.1/24 label eth0:0 dev eth0
2、创建配置文件
在/etc/sysconfig/network-scripts/文件下创建文件
vim ifcfg-eth0:0
BOOTPROTO=static
IPADDR=192.168.241.12
NETMASK=255.255.255.0
DEVICE=eth0:0
ONBOOT=yes
9、常用的网络管理类工具有哪些,并用示例形式描述他们的使用方法。
1、网络查看与配置(命令形式)
网络查看
ifconfig
ip addr show
网络配置
ifconfig eth0 172.24.200.1 netmask 255.255.255.0
ip addr add 172.24.200.1/24 dev eth0
2、路由查看与配置(命令形式)
路由查看
route
ip route show
路由配置
route add -net 224.0.0.0 netmask 240.0.0.0 dev eth0
ip route add default via 192.168.1.1 dev eth0
3、网络连接查看
ss
[root@localhost network-scripts]# ss -natl
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 *:22 *:*
LISTEN 0 100 127.0.0.1:25 *:*
LISTEN 0 128 :::22 :::*
LISTEN 0 100 ::1:25 :::*
netstat
[root@localhost network-scripts]# netstat -anlt
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN
tcp 0 52 192.168.241.10:22 192.168.241.1:14451 ESTABLISHED
tcp 0 0 192.168.241.10:22 192.168.241.1:2041 ESTABLISHED
tcp6 0 0 :::22 :::* LISTEN
tcp6 0 0 ::1:25 :::* LISTEN
10、Linux系统软件包管理方法(安装、升级、卸载等操作)有哪些,以及如何管理的。
redhat风格软件包管理
1、安装
rpm -ivh 软件包命(需要手动解决软件包依赖关系)
yum -y install 软件包名(可自动解决软件包依赖关系)
2、卸载
rpm -e 软件包名(需要手动解决软件包依赖关系)
yum -y remove 软件包名(可自动解决软件包依赖关系)
3、更新
rpm -U 软件包 直接安装一个新包
rpm -F 软件包 删除原有包重新安装一个高版本的包
yum update [package1] [package2] 升级所有包同时也升级软件和系统内核
yum upgrade [package1] [package2] 只升级所有包
11、如何使用发行版光盘作为yum repository,请描述该过程。
[root@localhost network-scripts]# mount /dev/cdrom /media/
[root@localhost network-scripts]# vim /etc/yum.repos.d/local.repo
[local]
name=local
baseurl=file:///media/
gpgcheck=0
enabled=1
12、写一个脚本,完成以下功能
(1) 假设某目录(/etc/rc.d/rc3.d/)下分别有K开头的文件和S开头的文件若干;
(2) 显示所有以K开头的文件的文件名,并且给其附加一个stop字符串;
(3) 显示所有以S开头的文件的文件名,并且给其附加一个start字符串;
(4) 分别统计S开头和K开头的文件各有多少;
#!/bin/bash
#
#
#
S=0
K=0
for i in `ls /etc/rc.d/rc3.d/S*`;do
echo "$i start"
let S++
done
for i in `ls /etc/rc.d/rc3.d/K*`;do
echo "$i stop"
let K++
done
echo "START is $S, STOP is $K"
13、写一个脚本,完成以下功能
(1) 脚本能接受用户名作为参数;
(2) 计算此些用户的ID之和;
#!/bin/bash
#
#
#
SUM=0
ID=0
[ $# -eq 0 ]&& echo "user $0 username1 usermane2 ..." && exit
for i in $* ;do
if id -u $i &>/dev/null ;then
ID=`id -u $i`
let SUM+=$ID
else
echo "no such user $i"
continue
fi
done
echo $SUM
14、写一个脚本
(1) 传递一些目录给此脚本;
(2) 逐个显示每个目录的所有一级文件或子目录的内容类型;
(3) 统计一共有多少个目录;且一共显示了多少个文件的内容类型;
#!/bin/bash
#
#
#
NUM1=0
NUM2=0
[ $# -eq 0 ]&& echo "use $0 directory1 dicectory2 ..." && exit
for i in $* ;do
[ ! -d $i ]&& echo "$i is not a directory"&&exit
done
for dir in $*;do
file $dir/*
NUM1=`file $dir/* |grep directory$ |wc -l`
NUM2=`ls $dir|wc -l `
let NUM3+=$NUM1
let NUM4+=$NUM2
done
echo "Directory num. is $NUM3"
echo "All files num. is $NUM4"
15、写一个脚本
通过命令行传递一个参数给脚本,参数为用户名
如果用户的id号大于等于500,则显示此用户为普通用户;
#!/bin/bash
#
#
#
[[ $# -ne 1 ]]&& echo "use $0 user name "&& exit
USER() {
NUM=`id -u $1`
if [[ $NUM -gt 500 ]];then
echo "$1 is a ordinary user"
else
echo "$1 is not a ordinary user"
fi
}
if id -u $1 &> /dev/null ;then
USER $1
else
echo " $1 is not a username"
fi
16、写一个脚本
(1) 添加10用户user1-user10;密码同用户名;
(2) 用户不存在时才添加;存在时则跳过;
(3) 最后显示本次共添加了多少用户;
#!/bin/bash
#
#
#
ADDUSER() {
useradd $1 &>/dev/null
echo "$1" | passwd --stdin $1 &>/dev/null
}
NUM=0
for ((i=1;i<=10;i++));do
if id user$i &>/dev/null ;then
continue
else
ADDUSER user$i
let NUM++
fi
done
echo "adduser num. is $NUM"
17、写一脚本,用ping命令测试172.16.250.20-172.16.250.100以内有哪些主机在线,将在线的显示出来;
#!/bin/bash
#
#
#
PING() {
if ping -w2 $1 &>/dev/null ;then
echo "$1 is online"
fi
}
for ((i=20;i<=100;i++));do
PING "172.16.250.$i"
done
~
~
18、打印九九乘法表;
#!/bin/bash
#
#
#
for ((i=1;i<=9;i++));do
for j in `seq 1 $i`;do
let b=$i*$j
echo -n -e " $j*$i=$b "
done
echo
done